รายงานล่าสุด NIST 2025: สรุปจุดเสี่ยงและแนวทางป้องกันภัยคุกคามจาก AI
รายงานล่าสุด NIST 2025: สรุปจุดเสี่ยงและแนวทางป้องกันภัยคุกคามจาก AI
Business
4 นาที
08 เม.ย. 2025
แค่ใช้ AI แล้วคิดว่าปลอดภัย อาจทำให้ธุรกิจของคุณเผชิญความเสี่ยงมหาศาล
National Institute of Standards and Technology (NIST) หรือสถาบันเทคโนโลยีแห่งชาติของสหรัฐฯ ได้จัดตั้งหน่วยงานเพื่อขจัดอุปสรรคที่ส่งผลกระทบต่อความสามารถในการแข่งขันของภาคอุตสาหกรรมมาอย่างต่อเนื่อง ล่าสุดในเดือนมีนาคม 2025 ได้เผยแพร่รายงาน “Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations (NIST AI 100-2e2025)” ซึ่งมุ่งเน้นไปที่ภัยคุกคามและช่องโหว่ของระบบ Artificial Intelligence (AI) และ Machine Learning (ML) โดยเฉพาะ Predictive AI (PredAI) และ Generative AI (GenAI) พร้อมนำเสนอแนวทางป้องกันเพื่อให้ AI มีความน่าเชื่อถือ ปลอดภัย และสามารถควบคุมได้ในโลกความเป็นจริง
เมื่อ AI เข้ามามีบทบาทในเศรษฐกิจดิจิทัลและชีวิตประจำวันมากขึ้น ความต้องการด้าน ความปลอดภัย (Security), ความทนทาน (Robustness) และ ความยืดหยุ่น (Resilience) ของระบบ AI ก็ยิ่งทวีความสำคัญ นั่นหมายความว่าการพึ่งพา AI เพียงอย่างเดียวโดยไม่มีมาตรการป้องกัน อาจทำให้เกิดความเสียหายร้ายแรงต่อธุรกิจและองค์กรได้
สรุปประเด็นน่าสนใจจากรายงานล่าสุดของ NIST
ในรายงานฉบับนี้ NIST แบ่งระบบ AI ออกเป็น 2 ประเภทหลัก ได้แก่✅ AI เชิงพยากรณ์ (Predictive AI – PredAI) ใช้ในการวิเคราะห์ข้อมูลและคาดการณ์แนวโน้ม
✅ AI เชิงสร้างสรรค์ (Generative AI – GenAI) ใช้ในการสร้างเนื้อหา ข้อความ รูปภาพ หรือสื่อดิจิทัลรูปแบบต่างๆ
แต่แม้ว่า AI จะช่วยเพิ่มประสิทธิภาพการทำงานได้มหาศาล หากไม่มีมาตรการรักษาความปลอดภัยที่เหมาะสม ก็อาจกลายเป็นช่องโหว่ให้เกิดการโจมตีได้เช่นกัน แล้ว AI ต้องเผชิญกับภัยคุกคามอะไรบ้าง? และเราจะป้องกันได้อย่างไร? มาหาคำตอบไปพร้อมกัน!
🚨การโจมตีในระบบ PredAI (Predictive AI)
PredAI คือระบบ AI ที่ใช้ในการ “ทำนาย” หรือ “จำแนก” จากข้อมูลที่ป้อนเข้า เช่น โมเดลจำแนกภาพหรือตรวจจับสแปม ในรายงานจะแสดงการโจมตีเหล่านี้ในลักษณะ “วงกลมแยกออกจากกัน” โดยมี “วัตถุประสงค์ของผู้โจมตี” เป็นจุดศูนย์กลางของแต่ละวงกลม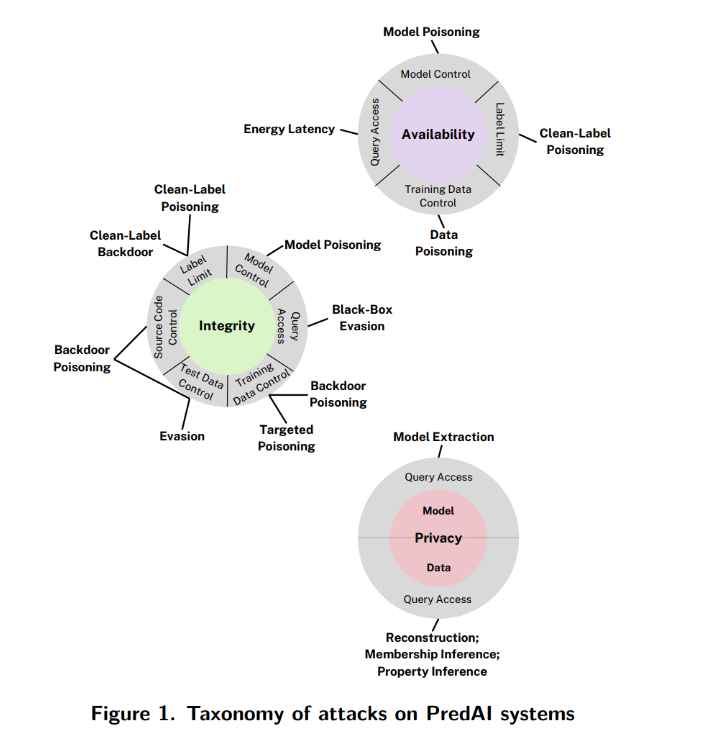
🎯 เป้าหมายของผู้โจมตี แบ่งออกเป็น 3 ประเภทหลัก
1. Availability Breakdown: ทำให้โมเดลทำงานช้า/ล่ม หรือไม่สามารถให้บริการได้ตามปกติ
วิธีโจมตี
- Data Poisoning: แทรกข้อมูลผิดๆ ลงไปในชุดฝึก
- Model Poisoning: แก้พารามิเตอร์ของโมเดล
- Energy-Latency Attack: เพิ่มภาระให้โมเดลตอบสนองช้าลง (แม้ไม่มีโค้ดของโมเดล)
วิธีโจมตี
- Evasion Attack: ปรับ input อย่างแนบเนียน เช่น เปลี่ยนภาพเล็กน้อยจนคนไม่สังเกตเห็น
- Poisoning Attack: ฝังข้อมูลผิดลงชุดฝึกเพื่อควบคุมผลลัพธ์ในบางกรณี
- Targeted Poisoning: โจมตีตัวอย่างเฉพาะ
- Backdoor Poisoning: ใส่ pattern ลับที่เรียกผลลัพธ์เฉพาะเมื่อมี pattern นี้
วิธีโจมตี
- Membership Inference: ตรวจว่าข้อมูลชิ้นใดอยู่ในชุดฝึก
- Data Reconstruction: สร้างข้อมูลต้นฉบับจากผลลัพธ์โมเดล
- Model Extraction: ขโมยพารามิเตอร์/โครงสร้างของโมเดล
🚨การโจมตีในระบบ GenAI (Generative AI)
GenAI คือระบบที่ “สร้างเนื้อหาใหม่” เช่น ภาพ ข้อความ หรือสื่ออื่นๆ เช่น GPT, DALL-E, Diffusion Models
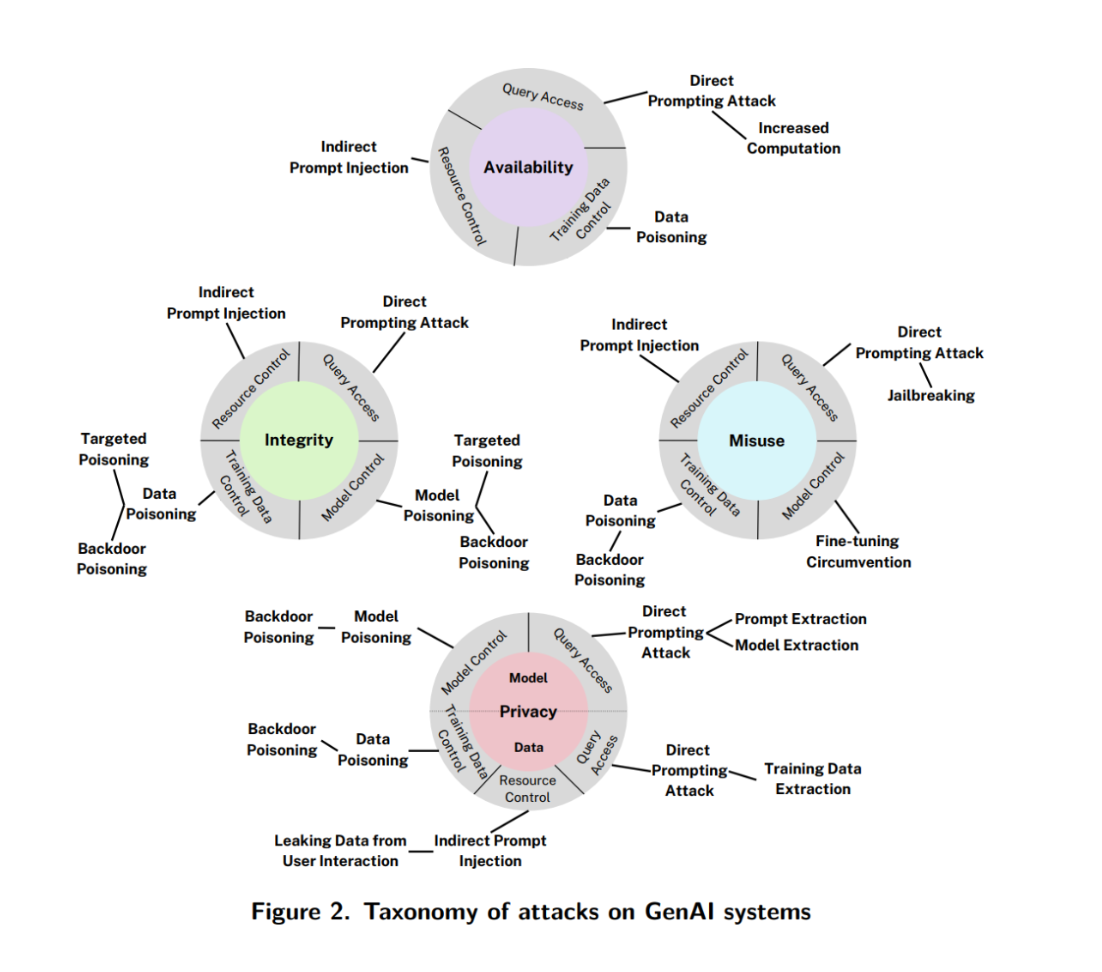
🎯 เป้าหมายของผู้โจมตีใน GenAI มี 4 กลุ่ม
1. Availability Breakdown: ทำให้ระบบสร้างผลลัพธ์ช้า ผิดพลาด หรือไม่ตอบสนอง
2. Integrity Violation: หลอกให้ระบบสร้างผลลัพธ์ที่ไม่ตรงวัตถุประสงค์ เช่น บิดเบือนเนื้อหาให้สื่อสารผิด
3. Privacy Compromise: ดึงข้อมูลที่เป็นความลับจากระบบ เช่น ข้อมูลฝึก หรือข้อมูลภายใน RAG system
วิธีโจมตี
- Indirect Prompt Injection: ฝังข้อมูลในเอกสารภายนอกที่ระบบนำมาใช้อ้างอิง
- Model Extraction: ขโมยพารามิเตอร์หรือความรู้ของโมเดล
วิธีโจมตี
- Prompt Injection: ฝังข้อความเพื่อหลอกล่อโมเดลให้ละเมิดข้อกำหนด
- Direct Prompting / Jailbreaking: ใส่ข้อความแนบเนียนเพื่อหลุดพ้นจาก system prompt
- Indirect Prompt Injection: ฝังคำสั่งผ่านแหล่งข้อมูลที่โมเดลไปเรียกใช้งานเอง
- Prompt Extraction: ดึงคำสั่งระบบที่ถูกซ่อนไว้ออกมา
- Agent Hijacking: หลอกให้ LLM-based agent ทำสิ่งที่ไม่ได้รับอนุญาต
รู้ว่าเสี่ยง แต่เลี่ยงได้! องค์กรจะรับมือกับภัยคุกคามจาก AI อย่างไร?
🔐 สำหรับ Predictive AIAdversarial Training: ฝึกโมเดลกับตัวอย่างที่โจมตีเพื่อเพิ่มความแข็งแกร่ง
Randomized Smoothing: ทำให้ผลลัพธ์ของโมเดลเสถียรขึ้นเมื่อมี noise
Formal Verification: พิสูจน์เชิงคณิตศาสตร์ว่าโมเดลจะไม่ถูกโจมตีบางรูปแบบ
🔐 สำหรับ Generative AI
Input/Output Filtering: ตรวจสอบ prompt และผลลัพธ์ที่อาจเป็นอันตราย
Segregated Prompt Channels: แยก “คำสั่งระบบ” ออกจาก “อินพุตของผู้ใช้”
การควบคุมข้อมูลฝึก / ระบบดึงข้อมูล RAG
Machine Unlearning: ลบข้อมูลของผู้ใช้ที่เคยใช้ฝึกออกจากโมเดล
สรุปรูปแบบการโจมตีของ AI ทั้ง 2 ประเภท

รายงานฉบับนี้ช่วยองค์กร ลดความเสี่ยงจาก AI ที่อาจถูกโจมตีโดยไม่รู้ตัว พร้อมแนวทาง ควบคุมต้นทุนความเสียหาย ที่อาจเกิดขึ้น เปรียบเสมือน “แผนที่นำทาง” สู่การออกแบบ AI ที่ปลอดภัย โปร่งใส และยั่งยืน เพื่อป้องกันภัยคุกคามใหม่ที่ระบบ IT แบบเดิมไม่เคยเจอ
📌 อ่านรายงานฉบับเต็มได้ที่ https://doi.org/10.6028/NIST.AI.100-2e2025
——
📌 สนใจ Corporate In-House Training ยกระดับทักษะองค์กรด้วย AI-People Enablement Solutions
ติดต่อ [email protected]
หรือโทร 082-297-9915 (คุณโรส)
——


